
Microbial biogeochemical models contain a large number of parameters that are needed to characterize microbial growth kinetics, such as maximum specific growth rate, half saturation constants and growth efficiency.
In Vallino (2000) we used data from a mesocosm experiment to estimate parameters in a microbial food web model used to simulate how bacteria use dissolved and particulate organic matter.
|
Microbial food web model focused on dissolved organic matter (DOM) utilized by bacteria (i.e., osmotrophs). The model uses 10 state variables to track both C and N flows, and has 29 unknown kinetic parameters. In addition, the initial conditions of the 10 state variables needed to be determined. (Click on image for larger picture.) |
| Mesocosm experimental treatments included (A) control (no additions), (B) organic matter addition, (C) nutrient addition and (D) organic matter plus nutrient addition. Microcoms were run for 21 days where nutrients concentrations and bacterial and primary productivity were measured daily. See here for more information. (Click on image for larger picture.) |  |
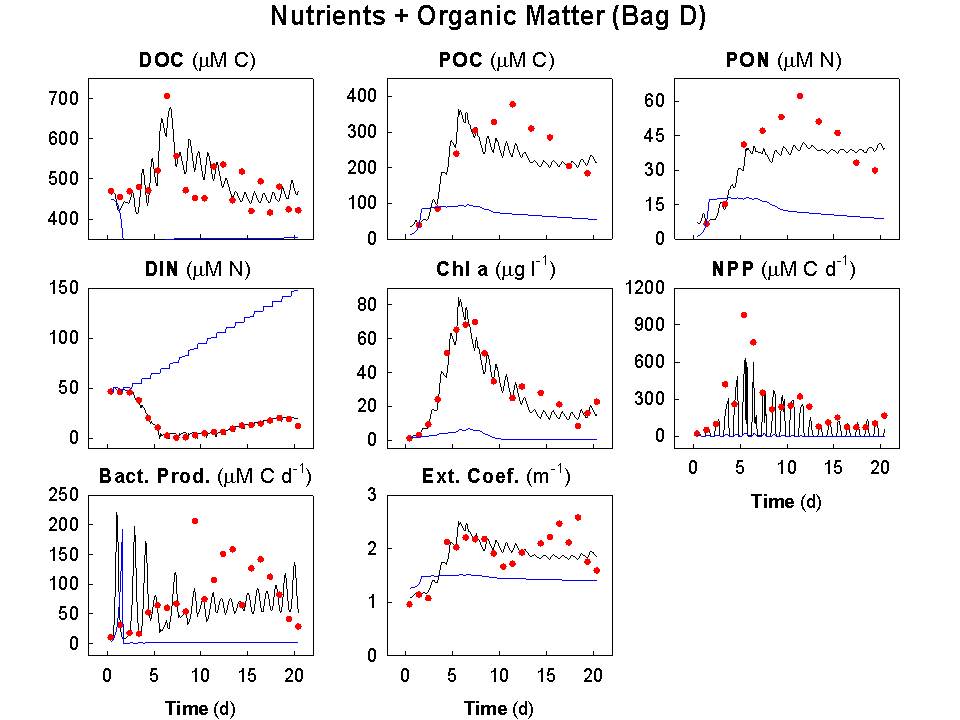 |
Example of model fit to data collected from treatment D. Blue line shows initial model simulation based on literature values for parameters, while black line shows model fit after data assimilation. (Click on image for larger picture.) |
As described in the manuscript we tested numerous optimization routines including both local and global optimization solvers (also see NEOS Optimization Software Guide). Interestingly, we found different solvers uncovered different parameter values that produced very similar model fits, which indicates unique solutions do not exist. Furthermore, we demonstrate that these types of kinetic-based food web models do not extrapolate well beyond the data they are calibrated with. The model can fit data from any one microcosm treatment, but does poorly when compared to data from other treatments not used in data assimilation. It appears that the large number of degrees of freedom allow the model to hide structural errors in the model equations that are only revealed when testing the model against new data.
A presenation of the work can also be found here.